Artificial Neural Networks
Advanced Modeling and Control
Biological Neuron
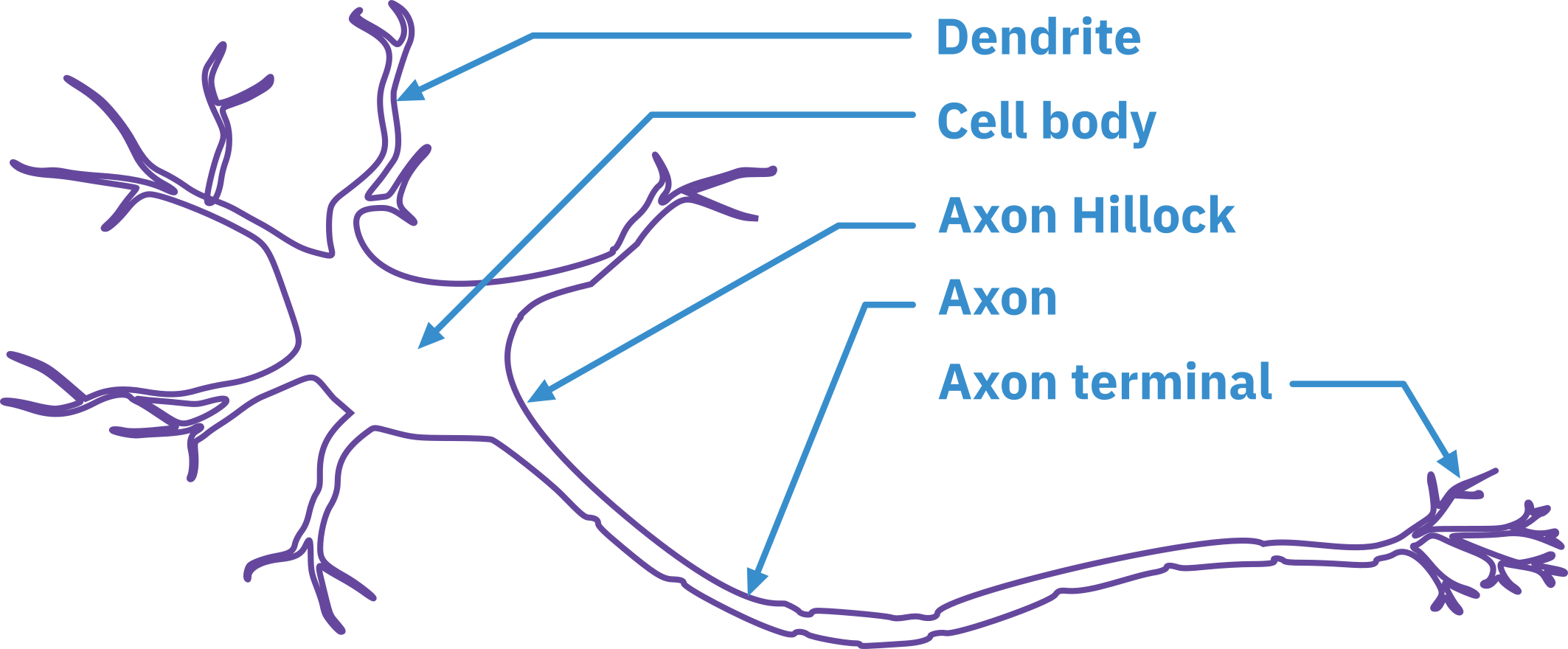
- Dendrite
- Receives and integrates synaptic signals from other neurons
- Cell Body
- Makes decisions based on integrated signals
- Axon
- Passes signals to other neurons
- Includes axon hillock (decision point) and axon collaterals (branches to nearby cells)
Many neuron types exist.
Interactions can be electrical or chemical.
Different types of neuron connections (e.g., axodendritic, dendrodendritic).
Key Characteristics of Neuronal Processing:
- Slow signal propagation.
- Large number of neurons (10^{10} – 10^{11}).
- No central controller (CPU).
- High connectivity (10^{4} connections per neuron).
- Information conveyed by neuron firing rates (activation).
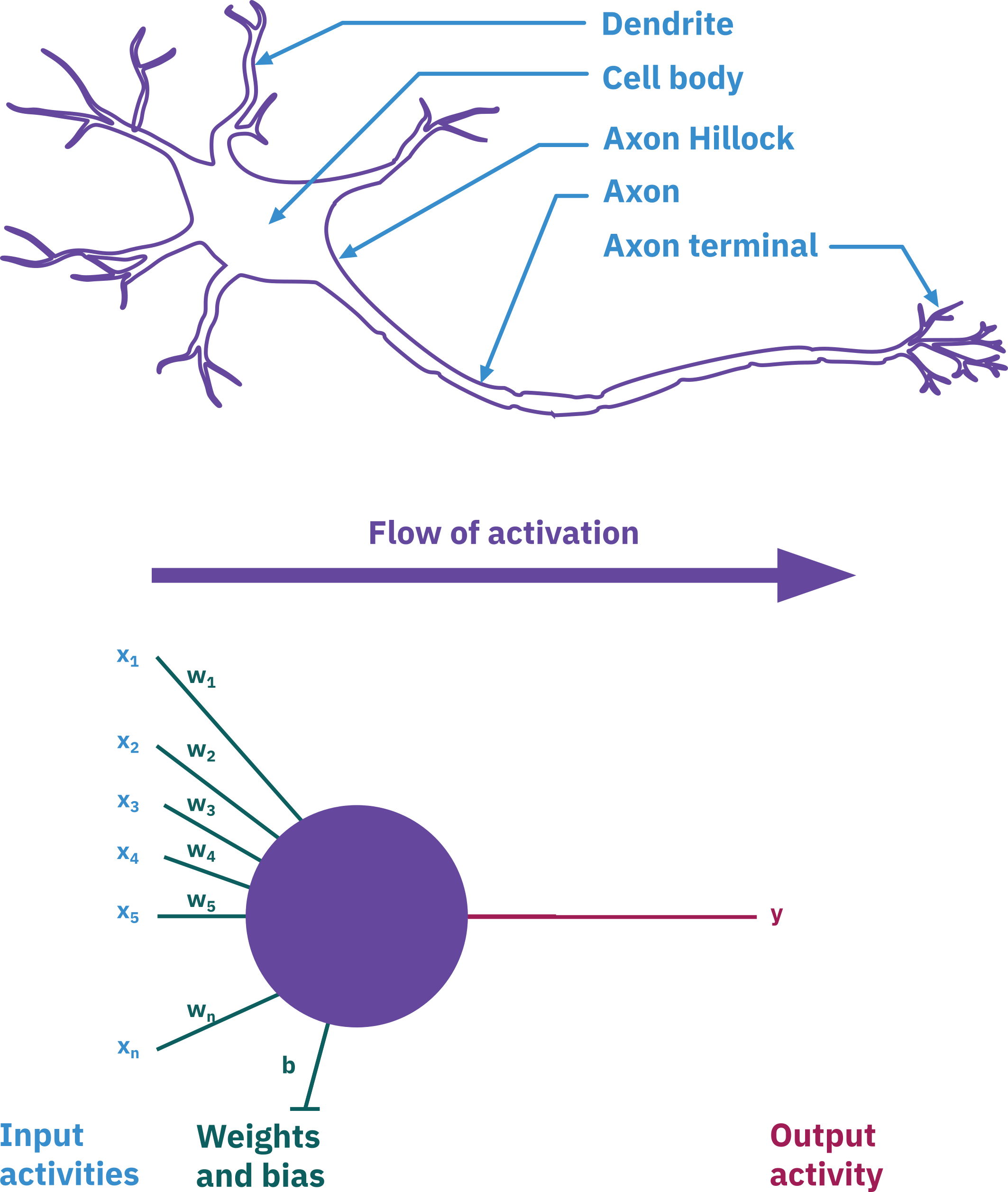
ANN basics: modeling single neuron
Universal Approximation Theorem
Any continuous function h(x) can be approximated by an ANN with one hidden layer, given appropriate non-linearity and sufficient neurons. Thus ANNs can model any complex, continuous function.
Neurons receive multiple inputs.
Inputs are modified by weights.
Neurons sum weighted inputs.
Neurons transmit output signals.
Outputs connect to other neurons.
Local Processing: Information is processed locally within the neuron.
Distributed Memory: Short-term = signals; Long-term = weights.
Learning: Weights adjust through experience.
Flexibility: Neurons can generalize and are fault-tolerant.
Elements of neural networks
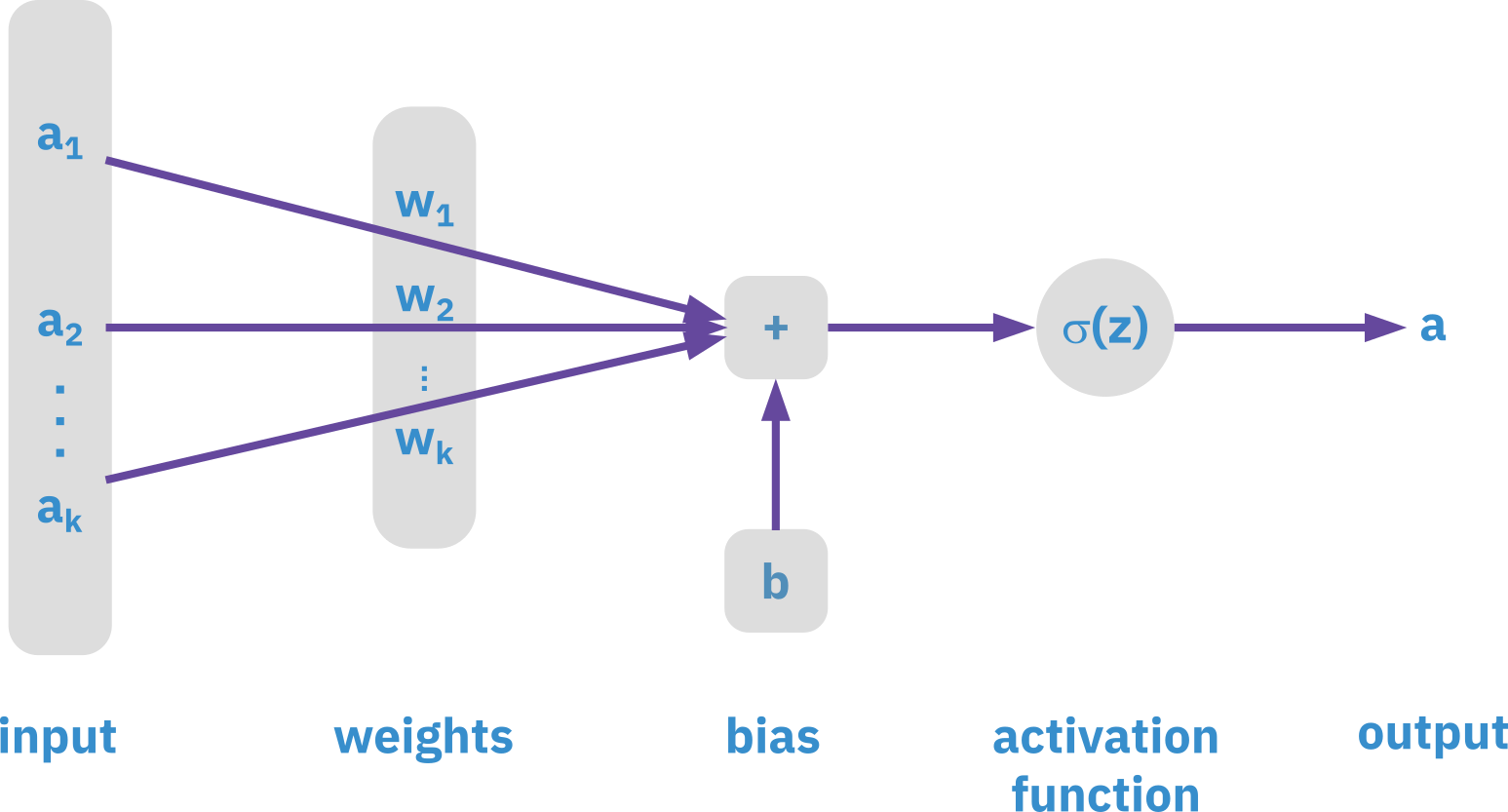
ANNs consist of hidden layers with neurons (i.e., computational units)
A single neuron maps a set of inputs into an output number, or f:R^K \rightarrow R
z = a_1 w_1 + a_2 w_2 + \ldots + a_k w_k + b; \qquad a = \sigma(z)
Elements of neural networks
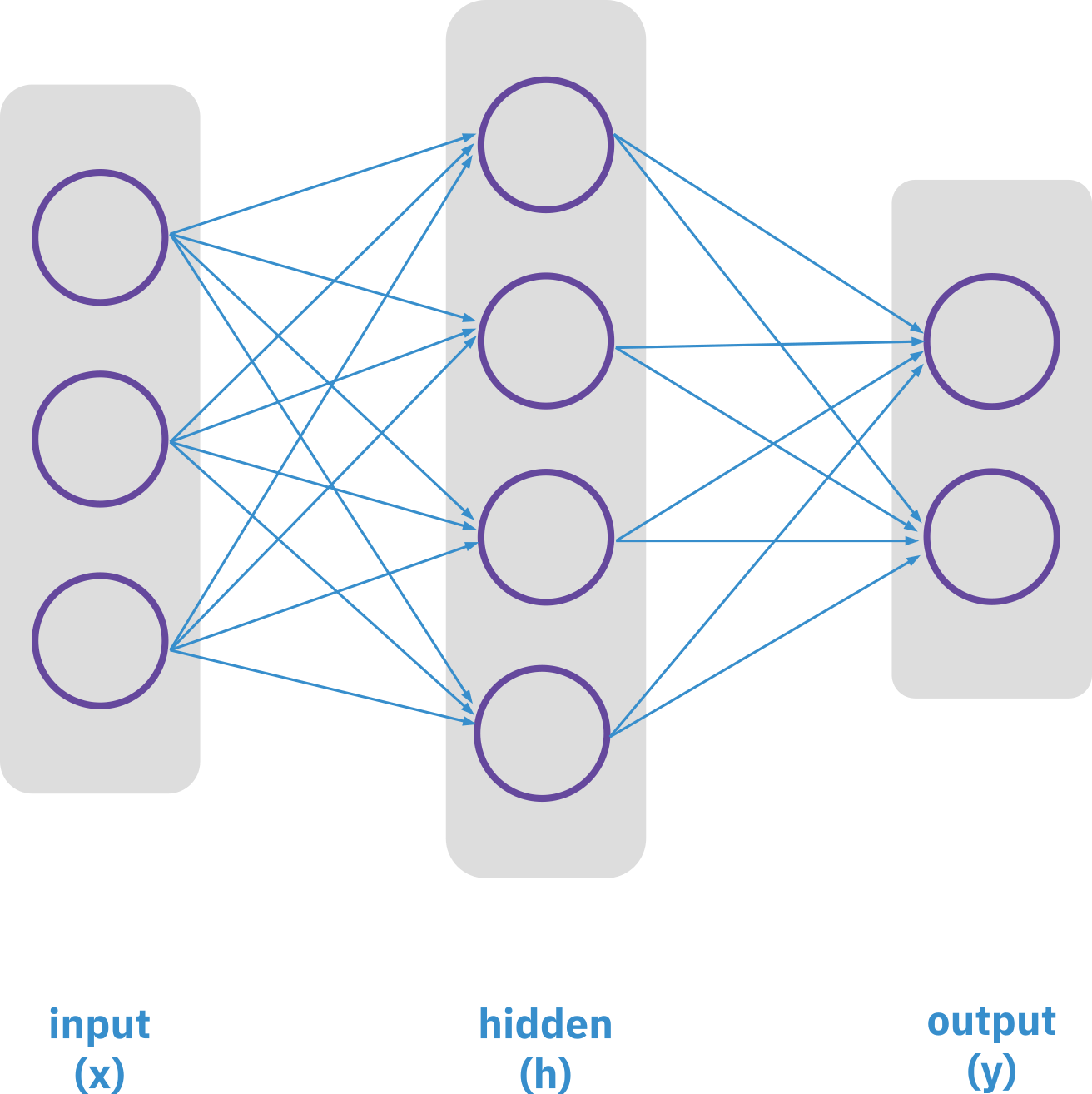
Hidden layer
h = \sigma (w_1 x + b_1)
Output layer
y = \sigma(w_2 h + b_2)
Neurons: 6
- Hidden layer: 4
- output layer: 2
Weights: 20
- Hidden layer: 3 x 4
- Output layer: 4 x 2
Biases: 6
- Hidden layer: 4
- Output layer: 2
Total 26 learning parameters
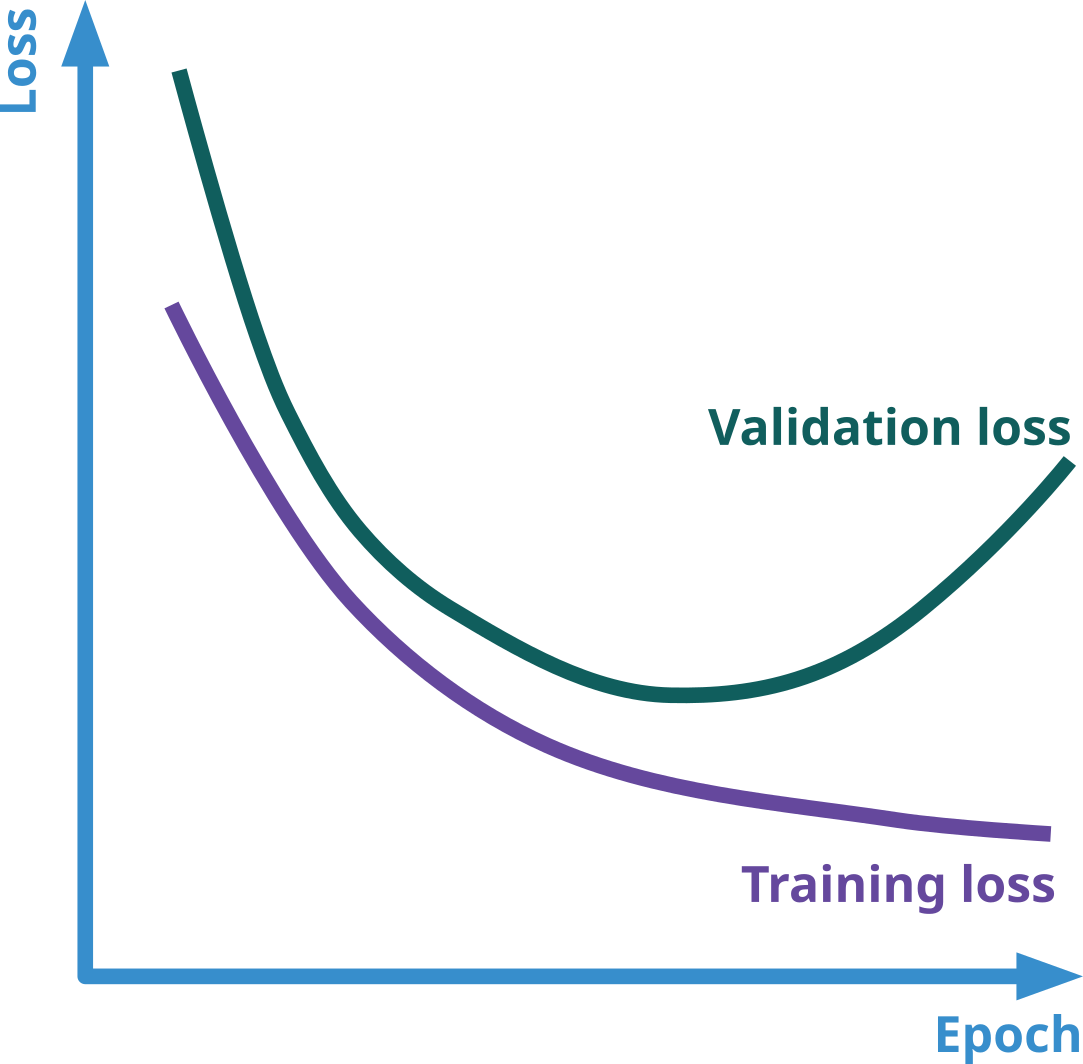
Overfitting
Overfitting occurs when a machine learning model learns not only the underlying patterns in the training data but also the noise and random fluctuations.
The model fits the training data too closely, capturing even the minor details and noise.
The model performs very well on the training data but poorly on new, unseen data
Causes
Too Complex Model: Using a model with too many parameters or features relative to the amount of training data.
Insufficient Training Data: When there isn’t enough data to represent the true underlying patterns, the model may learn noise as if it were a pattern.
Too Long Training: Training the model for too many iterations, allowing it to adjust to even the smallest noise in the data.
Overfitting mitigation strategies
Simplifying the Model: Reducing the number of features or parameters in the model.
Cross-Validation: ensure the model generalizes well to unseen data.
k-fold:
- divide the data into k subset
- Train the model k times. Each time one subset is used for validation and the rest are used for training
- Average the results
Regularization: Adding a penalty to the cost function for large coefficients
- L1: Helps the model focus on the most important features by setting some weights to zero.
- L2: Keeps all features but reduces the impact of any single feature by making all weights smaller.
Early Stopping: Halting the training process when performance on a validation set starts to degrade, even if the training performance is still improving.
Network Architectures
Perceptron & Feed-Forward Networks (FFN)
Basic prediction tasks, such as property estimation, reaction rate predictions, and process optimization.
Recurrent Neural Networks (RNN) & Long Short-Term Memory (LSTM)
Modeling dynamic systems, time-series data, and sequential processes, such as reactor dynamics and control systems.
Convolutional Neural Networks (CNN)
Primarily in image analysis related to process monitoring (e.g., analyzing images from reactors, identifying patterns in images of materials).
Autoencoders & Variational Autoencoders (VAE)
Dimensionality reduction, feature extraction, fault detection, and process monitoring.
Generative Adversarial Networks (GAN)
Generating synthetic data for simulations, improving the robustness of models, and process optimization.
